The Hadoop framework comprises of the Hadoop Distributed File System (HDFS) and the MapReduce framework. It divides the data into smaller chunks and stores each part of the data on a separate node within the cluster.
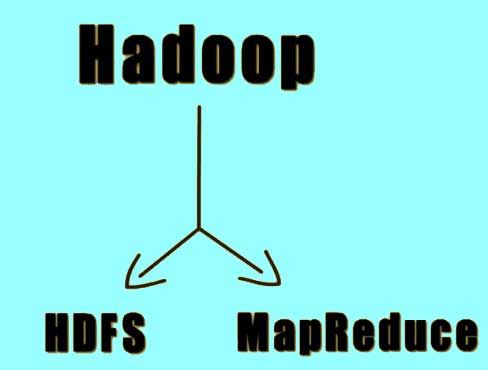
- Let us say we have around 4TB of data, and a 4 node Hadoop Cluster. The HDFS would divide this data into four parts of 1TB each. This would significantly reduce the time taken to store the data onto the disk. The total time required to store the entire data onto the disk is equal to storing one part of the data. This is because it will store all the parts of the data simultaneously on different machines.
- In order to provide high availability, Hadoop can replicate each part of the data onto other machines present in the cluster. The number of copies it can replicate depends on the replication factor. By default, the replication factor is set to three.
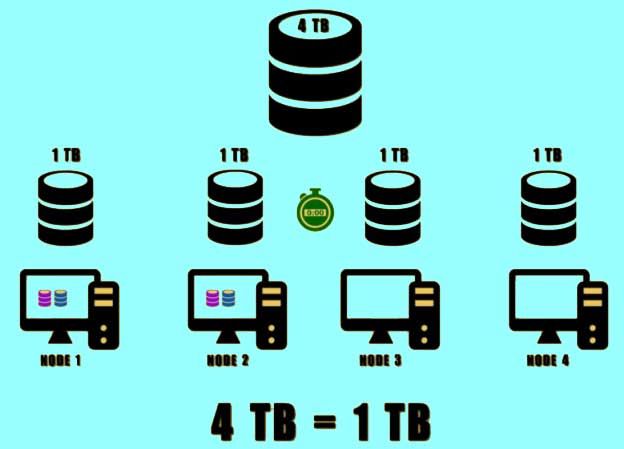
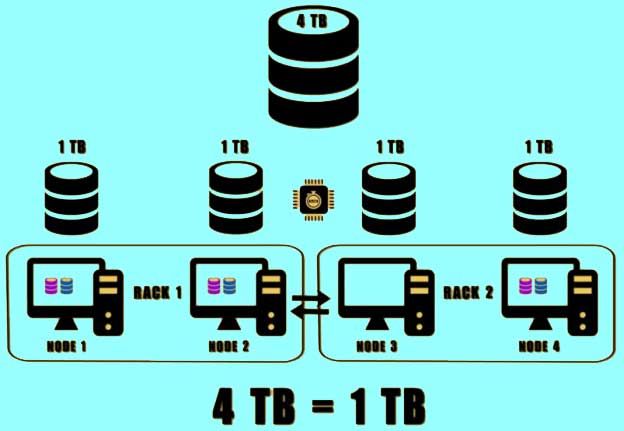
- Suppose the default replication factor is set then there will be three copies of each part of the data into three different machines. To reduce latency and bandwidth time it would store two copies of the data on the nodes present on the same rack. The last copy would be stored on a different rack.
- For example, if Node 1 and Node 2 are on rack one, and Node 3 and Node 4 are on rack two. Then the first two copies of part one would be stored on node 1 and node 2. The third copy will be stored either on Node 3 or on Node 4. A similar process is followed for storing remaining parts of the data.
- As the data is distributed across the cluster, the Hadoop networking system takes care of these nodes in order to communicate. It also reduces the processing time as a lot of data can be processed simultaneously.
Read Next Hadoop Ecosystem And Component