InterTopics of the Session:
- Concept of internal table
- Types of internal tables
- Declaration of internal table
- Commands related to internal tables
- Exercise
Internal Tables
- Database tables store long-life data
- Internal tables store temporary data
- Table calculations on subsets of database tables
- Implementing complex data structures
- Reorganize the contents of database tables according to specific processing needs
- Generate ranked lists
- Combine contents from more than one database table into a single table for easier processing
- Exist only at runtime, (unlike database tables)
- Consist of any number of records
Note: that it is not necessary to declare the initial size of the table: sap’s memory management allows the table to be ‘infinitely’ extensible.
Use of Internal Table
Internal tables can be used as:
- Snapshots of database tables
- Containers for volatile data
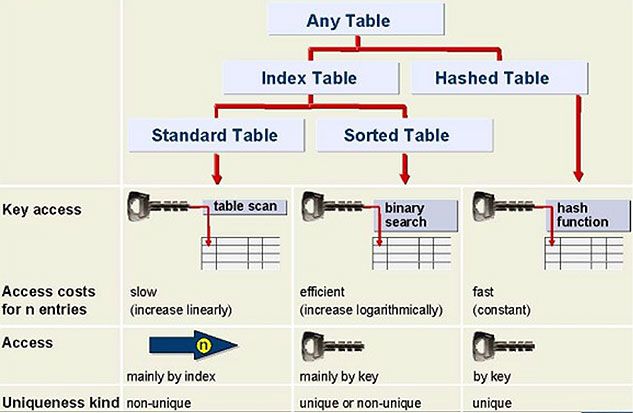
ABAP Internal Table Types
Choose table type (and access method) by most frequently performed operation
There are 3 ABAP Internal Table Types:
1) Standard Tables
- Access by linear table index or key
- Response time proportional to table size
2) Sorted Tables
- Filled in sorted order
- Access by linear index or sort key
Response time logarithmically proportional to table size
3) Hashed Tables
- Direct access (only) by table key
- Constant, fast response time
Internal Table Types
ABAP offers standard, sorted, & hashed types of internal tables. The type of table that you should use (and hence the access method) is determined by the operations that will be performed most frequently with the table.
1) Standard tables
Most appropriate for general table operations. Accessed by referring to the table index (which is the quickest access method). Access time for standard table increases linearly with respect to the number of table entries. New rows are appended to the table. Individual rows are accessed by reading the table at a specified index value.
2) Sorted tables
Most appropriate where the table is to be filled in sorted order. Sorted tables are filled using the INSERT statement. Inserted entries are sorted according to a sort sequence defined by the table key. Illegal entries are recognized as soon as you try to insert them into the table. Response time is logarithmically proportional to the number of table entries (since the system always uses a binary search). Sorted tables are particularly useful if you wish to process row by row using a LOOP.
3) Hashed tables
Most appropriate when access to rows is by a key. (Cannot access hashed tables via the table index)response time remains constant regardless of the number of rows in the table.
Hierarchy of Internal Table Types
Standard Tables (History)
Release 2.2
- Only standard tables with header lines
- Table structure determined with BEGIN OF <itab> OCCURS <n>… END OF <itab>.
Release 3.0
- Header lines optional
- Introduction of type concept
Release 4.0
- Introduction of sorted & hashed table types
- Allows key definition & uniqueness attributes
- Downward compatibility of 2.2 & 3.0 tables
Declaring Internal Tables
DATA:
- <itab> TYPE <itabkind> of <linetpye> [WITH [UNIQUE | NON-UNIQUE] <keydef>] [INITIAL SIZE <n>] [With header line].
- <itabkind> [STANDARD] TABLE | SORTED TABLE | Hashed table | any table
- <keydef> KEY <f1>…<fn> | Key table line | Default key
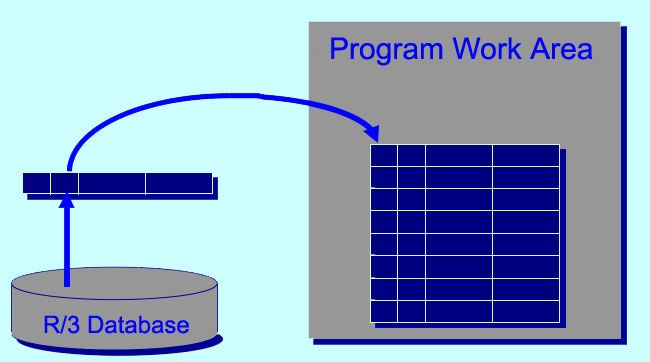
Tables With Header Line
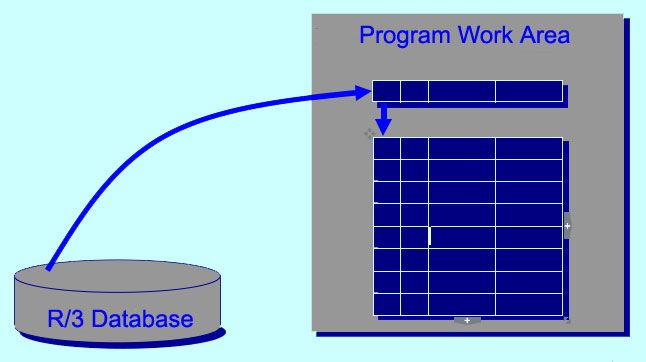
Tables Without Header Line
Header Lines Advantages and Disadvantages
Advantages of Header lines
1) Convenient declaration
- Table and header line structure declared in same statement
2) Ease of use
- Don’t have to explicitly move data into the work area structure and then append the work area structure to the table
3) Some statements require a table with header line
Disadvantages of header lines
- Performance - I/O is faster for tables without header line
- Cannot use in embedded structure
- Default declaration is without a header line
Declare a table with a Header line
Data: itab type standard table of <type> with header line
Types : Begin of GS_xtype,
var1 type c,
var2 type I,
.
.
End of GS_xtype.
Data book_tab type standard table of GS_xtype with header line.
Internal Table Definition Syntax
Standard Table Declaration
TYPES:
begin of LineType,
F1,f2,
End of LineType.
DATA:
itab TYPE SORTED TABLE OF
LineType WITH {NON- UNIQUE|UNIQUE} KEY f1
With header line.
Sorted Table Declaration
TYPES:
begin of LineType,
F1,f2,
End of LineType.
DATA:
itab TYPE SORTED TABLE OF
LineType WITH {NON- UNIQUE|UNIQUE} KEY f1
With header line.
Hashed Table Declaration
TYPES:
begin of LineType,
F1,f2,
End of LineType.
DATA:
itab TYPE HASHED TABLE OF
LineType WITH UNIQUE KEY f1 Initial size 100
With header line.
Declaring Internal Tables
1) with reference to existing internal or database table type
DATA <itab> type <tabtypedef> [WITH HEADER LINE].
2) with reference to an existing line structure
DATA <itab> like <tabtypedef> [WITH HEADER LINE].
4) Declaring Tables With a Header Line
Data: begin of itab occurs 1, Field1(8),
Field2 type i, … End of itab.
Types: begin of itab_type, Field1(8),
Field2 type c, … End of itab_type.
Data: itab type standard table of itab_type
With header line.
5) Declaring Tables Without a Header Line
Types: begin of itab_type, Field1(8),
Field2 type c, … End of itab_type.
Data: itab1 type standard table of itab_type.
Data: itab2 like itab1.
Note: Do Not Declare Internal Table This Way
Data: begin of INT_tab occurs 0, EMP_code type i, Name(20),
Join_date type d, End of INT_tab.
Accessing Internal Tables
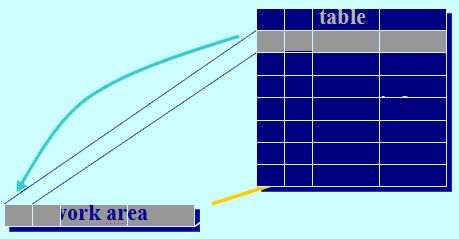
Work area acts as interface for transferring data
1) Read from table
- contents of table line overwrite work area
- program refers to work area
2) Write to table
- first enter data in the work area then transfer to table
Generic Key Operations
| KEY | Single record processing | Multiple record processing |
|---|---|---|
| Read |
| LOOP AT flab WHERE cond. |
| Insert | INSERT wa INTO TABLE itab. | INSERT LINES OF flab.; INTO TABLE itab2. |
| Change | MODIFY TABLE itab FROM wa. | MODIFY itab .. TRANSPORTING , WHERE cond. |
| Delete |
| DELETE itab WHERE cond. |
Clear, Refresh and Free Commands
Clear
- Deletes the content of the header area of internal table
- Does not delete the content of the internal table
Refresh
- Deletes the content of the internal table
- Does not delete the content of the header area
Free
- Frees the memory space allocated to the internal table
Data Transfer & Internal Tables
- Append, Collect, Insert
- Append, insert, move
- Loop, read, search
- Describe
1) Append
APPEND [ <wa> TO | INITIAL LINE TO] <itab>
Appends new line to itab <wa> TO specifies the source area <wa> INITIAL LINE TO appends line with each field set to default values according to field type To be used only with STANDARD table
Data:
itab type standard table of spfli ,
itab_wa like spfli.
Select * into itab_wa
From spfli.
Append itab_wa to itab. endselect.
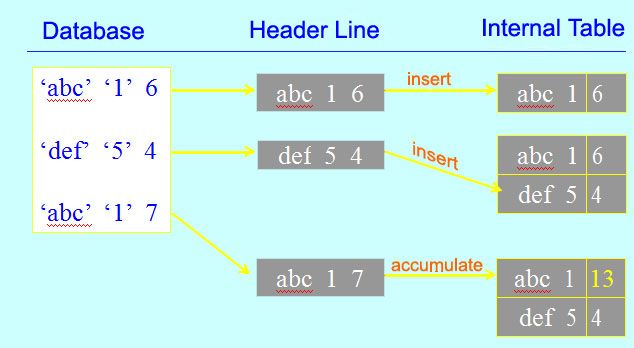
2) Collect
COLLECT [ <wa> INTO] <itab>
used to fill an internal table which has unique table key (or standard key for standard table if no key defined):
- standard key is a combination of non-numeric key fields
if table entry exists with the same table key values as the work area <wa> or the header line of the table
- COLLECT adds the contents of the numeric fields of the work area to contents of the numeric fields in the existing entry
else
- COLLECT is the same as APPEND
Often used to generate summary information
data: itab type standard table of sflight, wa like sflight.
select * into wa from sflight.
collect wa into itab.
endselect.
loop at itab into wa
write wa-carrid (standard key fields), wa-connid, wa_fldate, wa-seatsocc (sflight-seatsocc).
endloop.
Insert
INSERT [ <wa> INTO | INITIAL LINE INTO] <itab> [INDEX <idx>].
New line is inserted before the line which has index <idx>
- If the table consists of <idx>-1 lines the new line is inserted at the end of the table
- If INSERT is used without the INDEX addition it can be used only in a LOOP…ENDLOOP by adding the new line before the current line
- NB: insertion by index is not recommended for SORTED table nor permissible for HASHED table
System Fields Used in Table Processing
SY-TABIX
- Holds the index of the current line in the table
SY-SUBRC
- Return code for operation
SY-SUBRC = 0
- Operation was sucessful
SY-SUBRC <> 0
- Operation failed
SY-DBCNT
- Number of lines that were affected by the operation
- How many lines have already been processed
Copying Contents of an Internal Table
To append part or all of <itab1> to <itab2>
- APPEND LINES OF <itab1> [FROM <n1>] [TO <n2>] TO <itab2>.
To insert part or all of <itab1> into <itab2>
- INSERT LINES OF <itab1> [FROM <n1>] [TO <n2>] INTO <itab2> [INDEX <idx>].
To copy the entire contents of <itab1> into itab2>
- MOVE <itab1> TO <itab2>.
NB: again, inserting by index will create problem with SORTED table and not permitted with HASHED table