What is Secondary Name Node?
Role of Secondary Namenode in Managing the Filesystem Metadata.
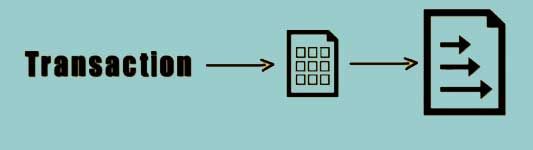
Each and every transaction that occurs on the file system is recorded within the edit log file. At some point of time this file becomes very large.
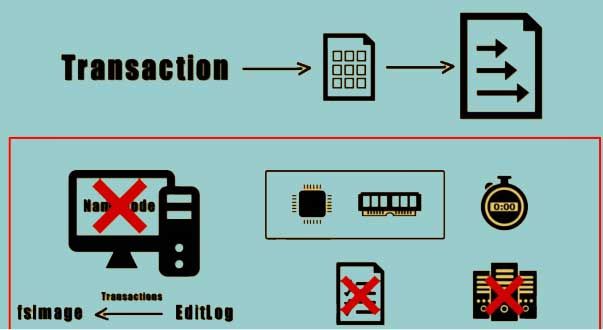
In such cases, if the Namenode fails due to corrupted meta data or any other reason than It has to retrieve the FS image from the disk and apply all the transactions to it present within the edit log file. In order to apply all these transactions, the system resources should be available. It also takes lot of time to apply all these transactions. Until all these transactions are not applied the contents of the FS image are inconsistent hence the cluster they cannot be operational.
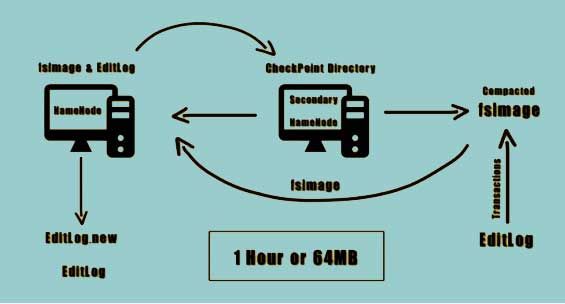
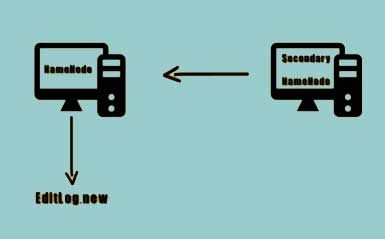
The secondary Namenode can be used to prevent the situation from occurring. The secondary Namenode instructs the Namenode to record the transactions to a new edit log file
The secondary Namenode copies the FS image and the edit log file to its checkpoint directory. Once these files are copied the secondary Namenode loads they FS image and applies all the transactions from the edit log file and stores this information onto a new and compacted FS image file.
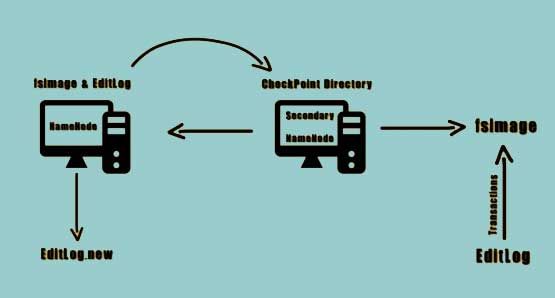
The secondary Namenode transfers this compacted FS image file to the Namenode. The Namenode adopts this new FS image file and also renames the new edit log file that was created back to edit log file. This process occurs every hour or whenever the size of the added Logfile reaches to 64 MB.