SAP HANA VORA is an interesting topic, originally developed as a part of a big data solution for providing an OLAP-like environment for analyzing data. But before getting into the VORA topics, let us first understand what Enterprise data is.
What is Enterprise data?
Enterprise data is a special form of data related to an enterprise. These data particularly comprises shared data by the different users of an organization, or customer data of any application, department data, or data from various geographic regions. Since data loss for a company can cost critical financial losses for all parties involved, they spend considerable time & resources on carefully and effectively managing, modeling, security, storage, and extracting data.
What is SAP HANA VORA?
SAP HANA VORA, also known as SAP Vora, is a tool that uses SQL-on-Hadoop for solutions. SAP developed it to perform operations on Big Data. It provides Online analytical processing (OLAP)-type environment that uses complex queries for analyzing aggregate enterprise data of your enterprise. Enterprises also use VORA to perform Big data analysis so that, companies can include their historical data for BI systems and effectively comprehend meaningful insight from data.
VORA runs its services on the Hadoop-based ecosystem. Also, it enables boosting Apache Spark's performance. Also, VORA can interpret data from SAP HANA to Spark as well as writes back the tables to HANA that makes it bi-directional. Vora is a tool that a company installs on all the employee's systems or nodes in the existing Hadoop cluster. It gets triggered for processing on each machine and keeps on run permanently.
Components in VORA:
There are different components and sub-components of SAP HANA VORA. VORA has a web-based user interface known as VORA tools.
Vora’s UI contains the following 3 components:
- Data browser: The Data Browser in SAP allows us to manage tables from the ABAP(a programming language developed by SAP) Data Dictionary. You can use this tool for effortless reporting.
- SQL Editor: SQL Editor is used for various statements related queries. You can execute SQL statements like simple, mixed, and even complex statements. This is the core component of Vora UI. You will require special permissions to use SQL editor and efficiently work on a database.
- Data Modeler: Data modeler is a tool created using ABAP to create models in accordance with SAP algorithms. You can also map your created models in the ABAP dictionary and reuse them at will.
The web UI gives a similar interpretation environment for Business Intelligence analysts. It, thus, excludes the necessity to learn new scripting languages such as Python, Java, or Scala. VORA tools also allow analysts to import & analyze data effectively with data modelers & perform querying using SQL. Therefore, analysts should have to be familiar with the scripts or scripting terminal shell and its scripting language. It is alike to creating data models in HANA, VORA that demands no learning curve.
Another component of HANA VORA is the pre-written Scala codes for performing business functions such as units of measurement, currency conversion, hierarchies, etc. These ready-to-use functions reduce time and effort in dealing with data modeling. Other data analytic scenarios demand standard data modelers (with operations like join, union, aggregations, etc.) to generate good enterprise data insights or getting a gist of the data since the quantity of data is massive.
Where to deploy SAP VORA?
Companies can deploy SAP HANA VORA on various platforms like Cloudera, Amazon EMR, MAPR, or Hortonworks. It also provides a test drive for VORA developer 1.2. Employees can deploy that test drive in Hortonworks. One can take that test drive for three hours without any fee. We can also get VORA developer 1.2 using the cloud library. If you wish to use VORA using AWS, you have to create an Amazon Web Service (AWS) account with a minimal fee of (.51 cents/hour).
The recent release of SAP HANA VORA version 1.3 comes with improved security for the enterprise-level by compelling user login for VORA tools. Apart from these, there is the VORA manager server available for monitoring server status & review the configuration details. VORA Tools also became event-driven, where it provides drop-down buttons for creating VORA tables as an alternative option to writing SQL scripts. Other highlights include data preview, parent-child hierarchy, and calculated columns.
Vora offers the following 3 plans to its users. Of course, you will pay accordingly.

Getting Started with Sap Hana Vora
Now, Let’s talk about how you can use Vora after deploying on-premise or cloud.
There are total 3 methods to interact with servers of Vora, They are as follows:
- The Vora Spark extension: This method allows you to write codes on SAP Vora tables. The SAP Vora and SAP HANA clients are used for this method. You can also use a data source. (Data source to be used is Vora Spark.)
- Thrift server and JDBC: We will set up a “thrift server” in this method. Drivers will be connected using these servers. And Then issue Spark SQL queries for the SAP Vora. Done, you have successfully installed SAP Vora on your host computer or cloud.
- ODBC method for Hana and Vora: In this method, we will access Vora servers from Hana servers using Smart Data Access. ODBC drivers will assist with this exchange. Furthermore, we will issue HANA SQL queries. SAP Vora contains some data and these queries will complete the final interaction.
Refer to this image to understand the overview:
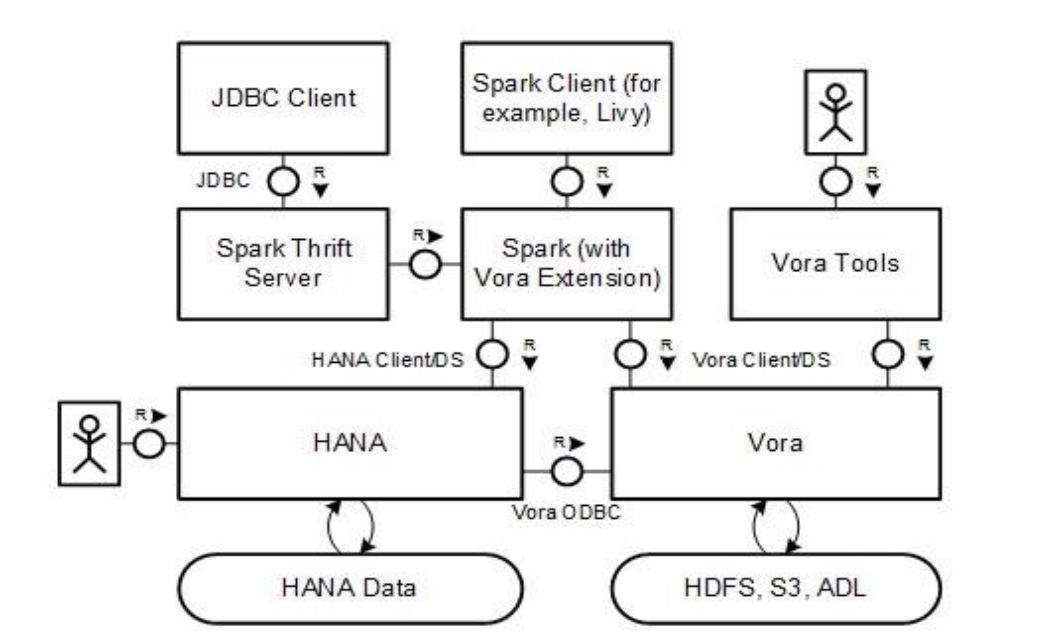
Architecture Review of Sap Hana Vora
Sap Hana Vora uses this basic architecture structure to deliver database management. We already mentioned all the components of Vora. Now, we will describe interconnection within the different components and data flow.
In the above figure, Enterprise data is being stored in the Hana container and Big data is being stored using Hadoop clusters. Vora makes big data more available to Enterprise data. This makes it easy to run queries involving both the data.
Vora makes it possible to manage any type of data and provides the users with the interactive UI to manage their files.
Vora is the inbuilt engine integrated to work with the sparks framework to manage the large data distributed in different Hadoop nodes.
Vora uses the concept of connectors that acts as a bridge between Big data and Enterprise data. Vora connectors are responsible for making available the Big data to the Hana server and manage them in a single place.
Hana can also retrieve the previous versions of data from the backups and can combine it with the Hadoop big data to execute the query. You can even use archived data to process queries using this method.
SAP Vora version 1.4 comes with the support of new data types:
- Relational data
- Graphical data
- Collections of JSON
- Advanced time series.
Unique search engines are assigned for dedicated data types. This allows bug free and fast results. These engines have specific algorithms to process the desired
- Relational in-memory engine: This engine allows you to load relational data into primary memory which in turn allows fast access for code generation and processing queries.
- Relational disk engine: Main memory does not allow data sets for the relational data type. This engine completes the host memory by adding data sets for relational data processing.
- Time series engine: Time series data needs to be compressed. It is bulky and can slow down your work. So this engine compresses data using SAP developed algorithms. Not only this, but It also provides different in-built algorithms like cross correlation or histogram computation for the compressed data.
- Graph engine: This engine lets you perform a graphical operation on your data. This is majorly used for handling complex analytical queries on very large graphs or graph-based data.
This all summarizes the basic architecture used by SAP Hana Vora. Understanding this allows you to use Vora techniques to their full potential.
Update in SAP Hana Vora architecture
In recent trends, there have been many updates in the architecture of Sap Hana Vora. Unlike the previous version 1.0 of Vora, the Latest version (2.0) made Vora to be containerized. In simple words, now users can integrate Kubernetes and Docker containers to deploy, scale and manage large data.
Earlier users had to set up a separate container-orchestration system which was an extra expense. Now you can easily integrate Docker and Kubernetes to enhance your database management.
What is Docker and why does SAP Vora need it?
It is a basket of platforms that provides service products. Docker uses some OS-level methods to create a virtual package of software. These packets are called containers and are sent through well defined channels. Every channel is isolated.
Docker allows you to transfer your desired software directly from your host computer. This helps you to manage data effortlessly. Docker also allows you to manage your host computer in the same way you manage your applications.
Docker creates easy to track channels for SAP Vora. SAP takes care of infrastructure and deployment but you will need Docker to take care of containers involved with running a database.
What is Kubernetes?
It is an open source software that manages Linux container operations. It supports the deployment, scaling, and management of these projects.
You can easily cluster up hosts working on Linux containers. Kubernetes allows you to manage these clusters effortlessly. Cloud based web hosting has evolved and Kubernetes provides one of the best solutions.
Use of Kubernetes in SAP Hana Vora
SAP and Kubernetes work hand in hand. SAP Vora is deployed and run in Kubernetes clusters.
SAP Vora allows you to access various external data stores. Like, Azure, Hadoop, Spark, etc. SAP Data Intelligence System Management is required to run these data stores on SAP Vora.
Here, Kubernetes comes into play. System Management integrates easily with Kubernetes. System Management enables user applications to be dynamically created as Kubernetes pods that you can arrange and manage in Vora.
Integration of SAP Vora with Hana 2.0
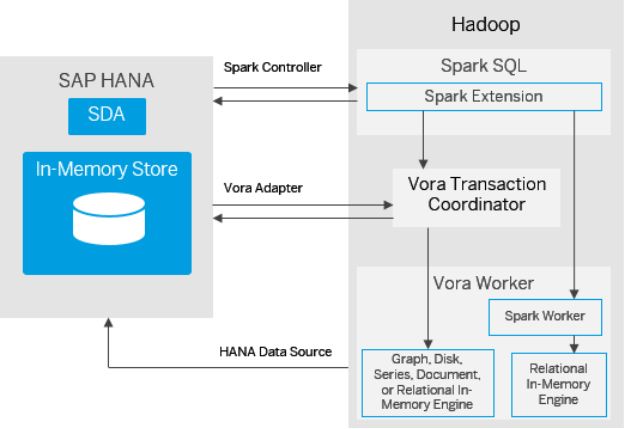
SAP Vora can be integrated with SAP HANA easily. We can achieve this in two different ways. Ultimately we will combine query in both SAP HANA and SAP Vora:
Using the SAP HANA data source extension
Spark data requires an implementation code to start the process. This code is contained in the SAP Vora Spark extension. You can utilize this data to communicate with HANA servers. And that’s how Spark applications can create an easy channel to facilitate data share between SAP HANA and SAP Vora.
Hadoop manages the data by using the Spark framework extension. Spark itself is an in-memory engine that facilitates the users to perform SQL queries very efficiently.
Using HANA SDA and the VoraODBC protocol
HANA SDA allows you to set up an isolated source for SAP Vora. Simply your SAP becomes a remote source.
Tables and data handled by SAP Vora can be shared to the HANA catalog as virtual tables and virtual data packets. Queries from SAP HANA in the form of virtual tables are then used in the next step.
Then the queries from HANA systems go through the Vora system. Exchange of data will happen now. Query execution will occur at Vora servers through Hana.
The attached image explains the integration structure of SAP HANA and SAP Vora.
Quick Wrap-up
We can summarize our article as:
There are two different versions of Sap Hana Vora. In the first version, we explained the architecture and concluded that it uses the Hadoop clusters to store the Big data in a distributed fashion.
Then we discussed Vora 2.0. In which Vora uses Kubernetes and Docker containers to deploy the projects. It made the architecture containerized. Hence, it makes the process faster and also provides auto manageable nodes.
Then these nodes offer an auto fault-tolerance feature that makes the system robust. Finally, We explained Docker to make you understand their role in the latest architecture of Vora.
At last, we explained the additional features of Vora 2.0 so that you can choose your product with complete knowledge.
Also, If users wish to shift from Vora 2.0 version to Vora 1.0, they can easily do it as Vora is backward compatible.
So, to make use of additional features, We recommend you shift into Vora 2.0 technology. It will leverage your Business both economically and strategically.